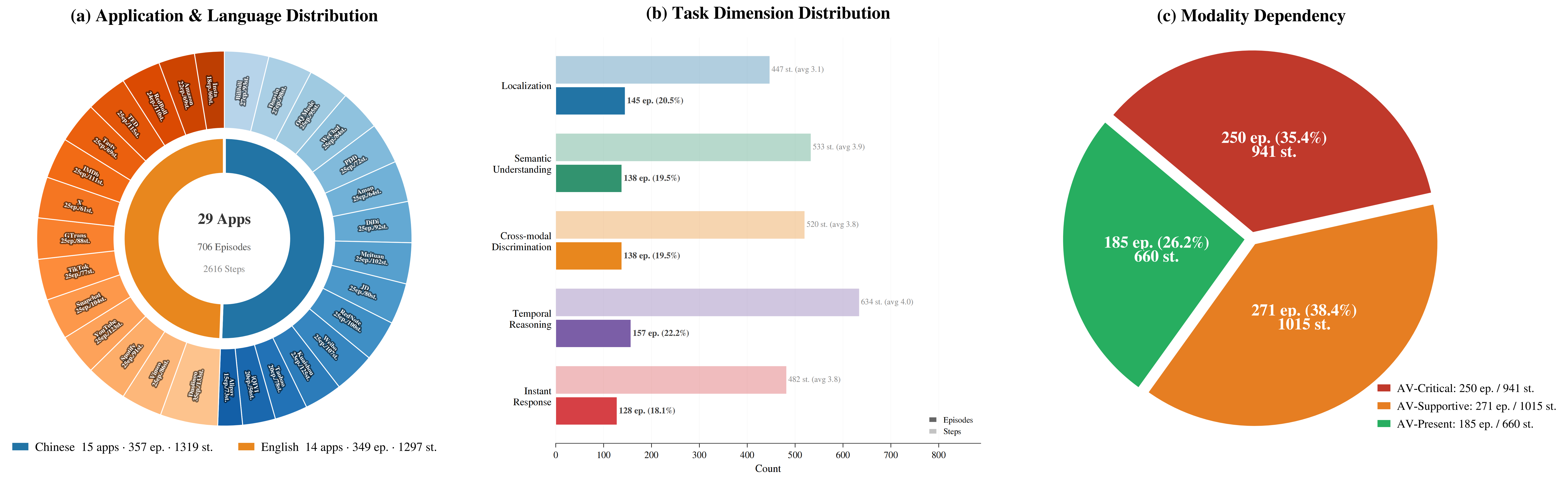
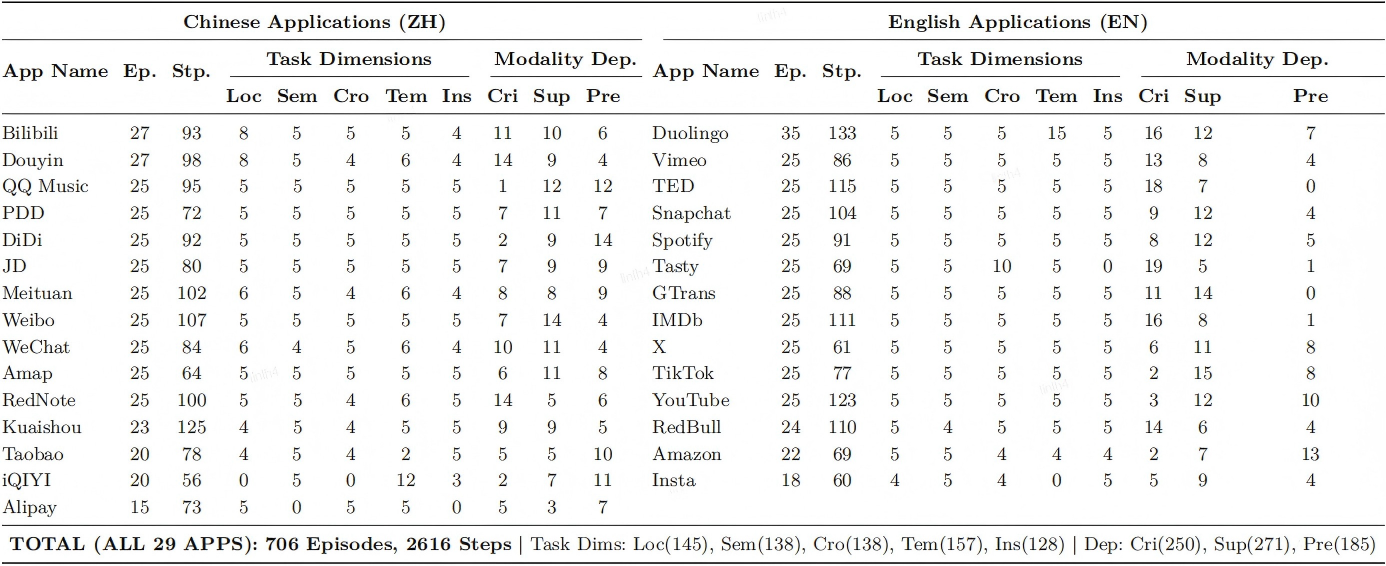
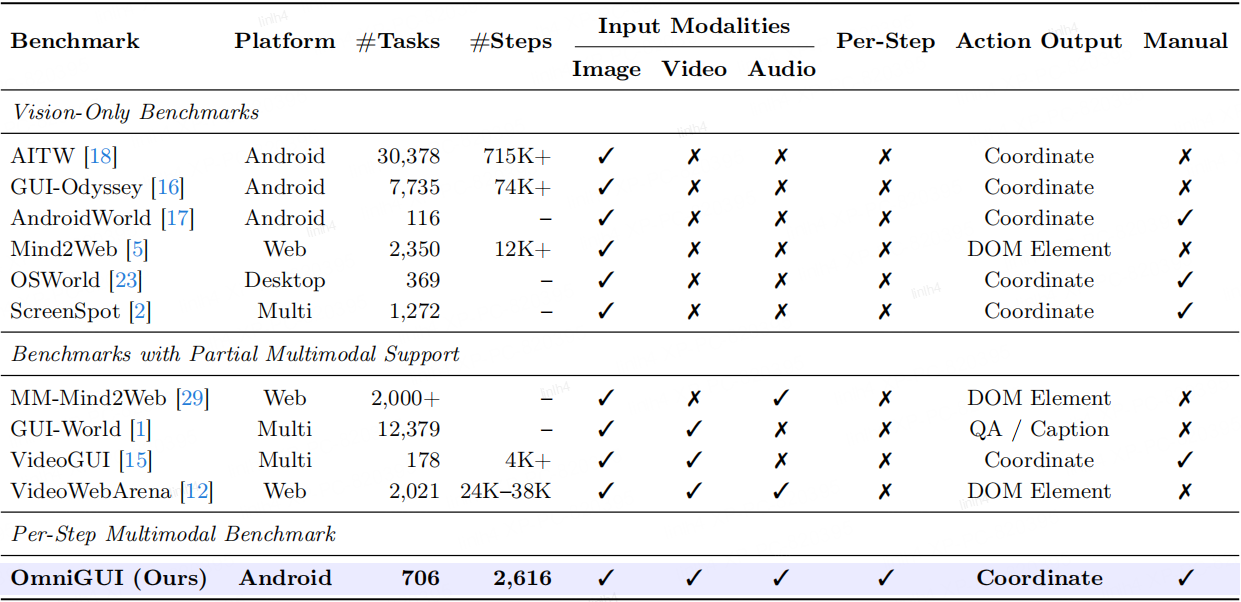
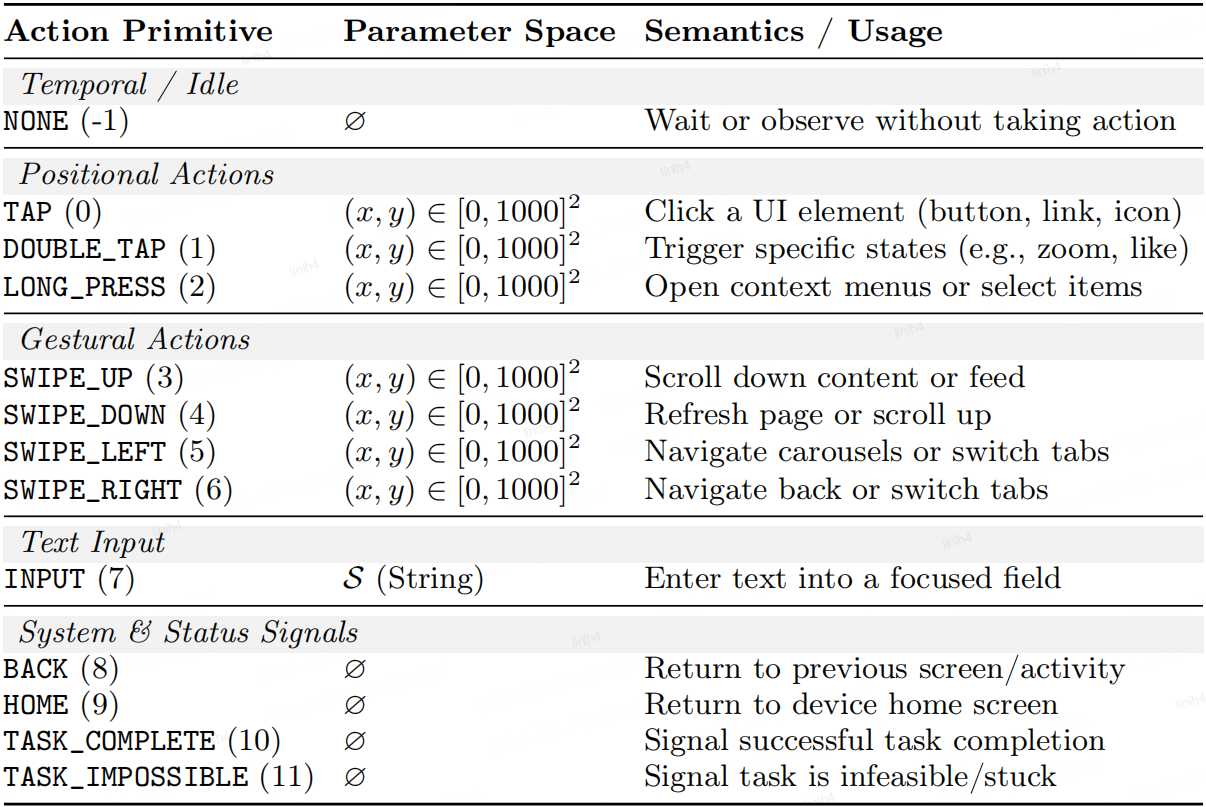
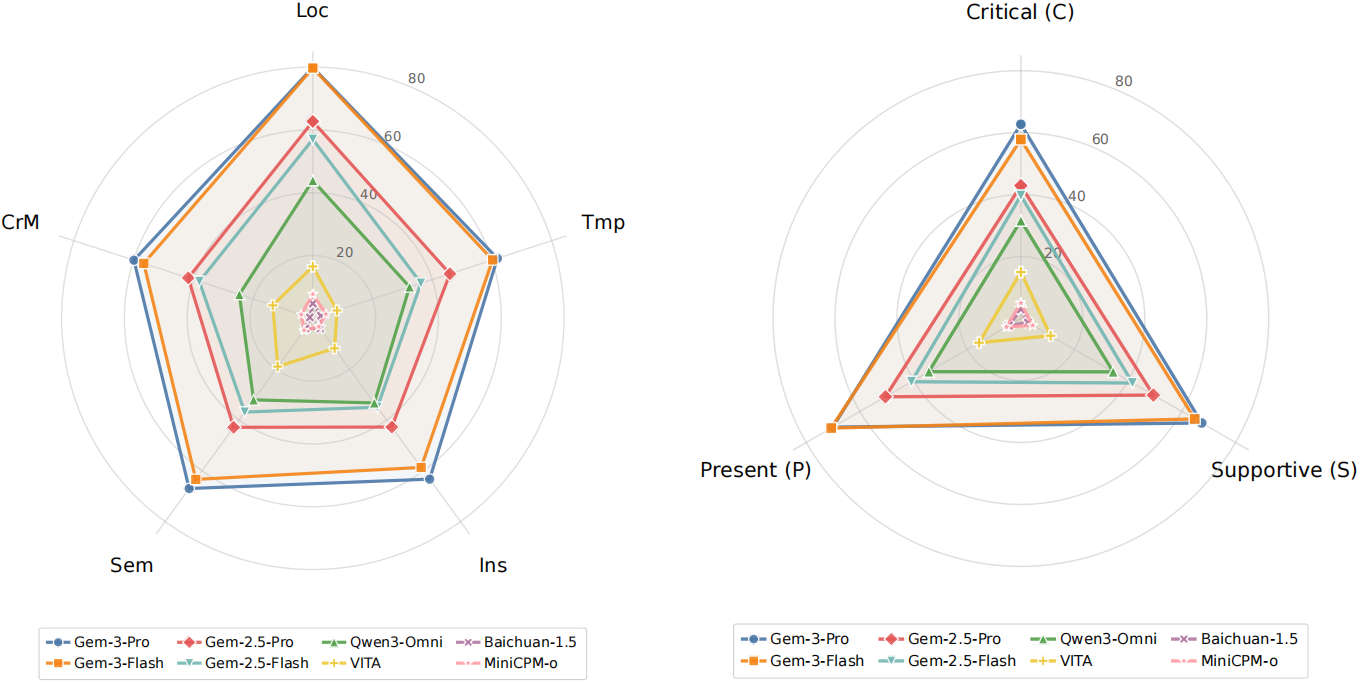
| # | Model | Localization | Semantic Understanding | Cross-modal Discrimination | Temporal Reasoning | Instant Response | Overall | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TM | EM | SR | GP | TM | EM | SR | GP | TM | EM | SR | GP | TM | EM | SR | GP | TM | EM | SR | GP | TM | EM | SR | GP | ||
| 1 | Gemini 3 Pro | 86.3 | 76.2 | 55.9 | 62.6 | 77.4 | 61.1 | 31.4 | 42.0 | 76.6 | 59.1 | 30.1 | 41.3 | 78.9 | 61.0 | 22.7 | 36.9 | 81.8 | 62.7 | 27.6 | 35.6 | 80.0 | 63.6 | 33.4 | 43.6 |
| 2 | Gemini 3 Flash | 85.0 | 75.6 | 53.1 | 63.1 | 75.3 | 58.5 | 25.5 | 41.1 | 72.8 | 56.0 | 23.5 | 38.7 | 80.0 | 60.3 | 25.3 | 39.4 | 79.2 | 57.9 | 22.8 | 34.2 | 78.3 | 61.3 | 30.3 | 43.5 |
| 3 | Gemini 2.5 Pro | 86.1 | 58.1 | 31.7 | 41.5 | 72.8 | 37.7 | 11.7 | 22.4 | 70.6 | 40.1 | 13.2 | 25.1 | 73.8 | 44.3 | 9.7 | 22.5 | 76.6 | 42.1 | 11.0 | 19.5 | 75.7 | 44.1 | 15.5 | 26.3 |
| 4 | Gemini 2.5 Flash | 75.1 | 50.9 | 29.0 | 42.6 | 70.4 | 34.3 | 8.0 | 18.2 | 64.9 | 35.7 | 11.8 | 25.3 | 67.7 | 35.1 | 9.1 | 21.8 | 71.0 | 34.5 | 3.9 | 13.7 | 69.5 | 37.8 | 12.4 | 24.5 |
| 5 | Qwen3-Omni | 65.7 | 42.4 | 10.3 | 28.5 | 58.3 | 29.6 | 2.9 | 14.0 | 57.9 | 26.2 | 2.2 | 13.2 | 66.2 | 31.1 | 5.8 | 16.8 | 67.4 | 33.7 | 3.9 | 13.7 | 63.1 | 32.3 | 5.1 | 17.4 |
| 6 | VITA-1.5 | 48.4 | 14.8 | 2.8 | 3.9 | 43.4 | 16.4 | 2.2 | 3.2 | 33.9 | 11.5 | 0.0 | 0.8 | 35.4 | 7.7 | 0.6 | 2.0 | 36.9 | 10.3 | 0.0 | 0.8 | 39.3 | 12.1 | 1.1 | 2.2 |
| 7 | MiniCPM-o-4.5 | 34.8 | 7.4 | 0.7 | 2.2 | 34.7 | 5.5 | 0.0 | 1.0 | 25.2 | 4.4 | 0.0 | 2.2 | 34.8 | 3.9 | 0.0 | 0.6 | 33.3 | 3.2 | 0.0 | 0.8 | 32.8 | 4.8 | 0.1 | 1.4 |
| 8 | Baichuan-Omni-1.5 | 19.5 | 4.9 | 0.0 | 1.0 | 16.2 | 4.0 | 0.0 | 0.5 | 12.9 | 1.4 | 0.0 | 0.0 | 18.2 | 2.3 | 0.0 | 0.2 | 18.2 | 4.1 | 0.0 | 0.5 | 17.0 | 3.3 | 0.0 | 0.4 |
* TM: Type Match, EM: Exact Match, SR: Success Rate, GP: Goal Progress.